The great thing about the Internet is that you can access knowledge anytime, anywhere. Furthermore, the Internet influences democracy in a way that anyone can participate in it. Just like a library that houses a lot of books, the Internet is ever-growing as more people contribute to it. It is also ever-changing, with new ways of displaying content being invented.
The beauty of the World Wide Web is how it is designed to be decentralized, but at the same time it is also an issue. With how it is structured, link rot, where over time resources or hyperlinks are either relocated or become permanently unavailable, and content drift, where the link does not point to its originally targeted source, are endemic to the web. As tweeted by Robyn Caplan, the Internet is forever, until you decide to go back in time.
The Internet is not forever.
With the rise of the Internet, more and more content is now being published digitally, which often doesn’t have a physical counterpart. This has led to issues when one needs to reference a link, such as in a research article. In an effort to fix this, websites such as Internet Archive and Perma have been created to create permanent records of the web.
However, in time, we can’t be sure whether these sites will still be available over many millennia. Since technology rapidly changes, not only the way we display content but also the hardware and software one uses will be greatly different to the one that will be used in the future. Moreover, we, as the people responsible for web standards, may even be the problem, just like how the great Library of Alexandria fell due to human casualty of war.
With that, I believe that a simpler and more distributed format is needed when we want to archive the web. I believe that every public web page should have an exportable format in which anyone can save locally.
Trying to think of a solution - Offline Web Surfing
Since archiving web pages is a topic I am interested in, I decided to list out all that I need in order to make offline web surfing work and sketch out how the architecture would look like.
In terms of offline web surfing, I am thinking of a flow like this:
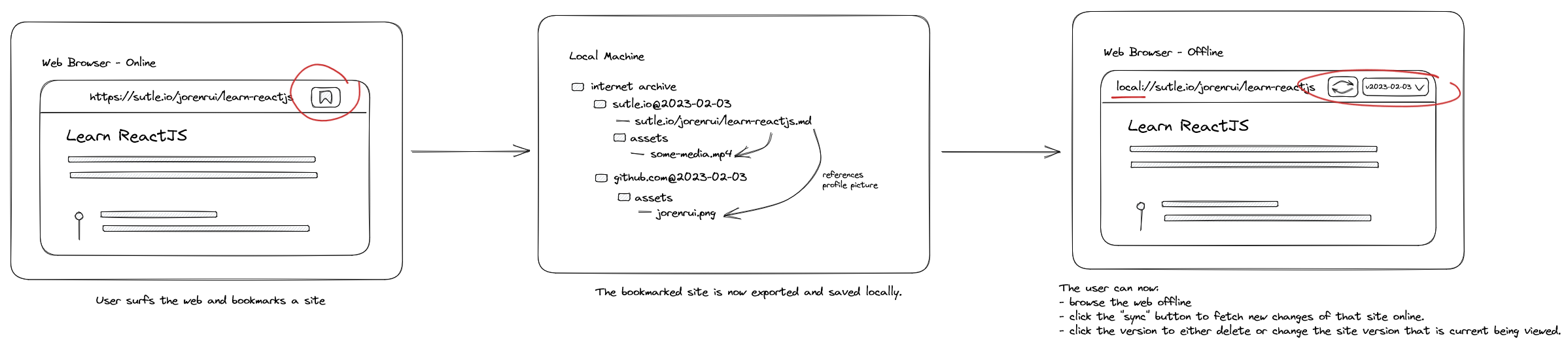
The bookmarked sites are saved locally which is like having your own local library of books (sites).
Then for the flow when the user visits an unavaible link then checks the online libraries if it has a copy:

Universal Format for the Content
When you think about it, the web started off in a simpler format. The Web 0.1 was a read-only Internet that web pages were written with a simple HTML code. But in Web 0.2, web pages weren’t static anymore. This gave rise to web applications that allowed users to interact and send data. With this, it became too difficult to parse the HTML code of a page due to the complexity of the app.
Sadly, there is no standard way of exporting a page. If you try printing a PDF (Ctrl + P on Windows) in a complex web app like Twitter, you will get a PDF that contains no main content besides the navigation.
So far, I don’t know of any standards for exporting web pages. If you know of any, I would love to know about it. Hopefully, there is something similar to RSS, where you just need to output an rss.xml file for your blog content, and then you can use RSS readers like Feedly to subscribe to blogs.
Currently, I was envisioning something that is similar to the simpler HTML structure before, or even just a Markdown or JSON file.
I guess for my portfolio, the markdown result would be:
---
- title: "Joeylene Rivera | Software Engineer"
- description: "Loves building products. Currently building sutle.io. Uses code to solve mostly my own problems. Has a thing for simplicity, knowledge, and problem solving."
- icon:
- "32x32": "https://joeylene.com/favicon/favicon-32x32.png"
- "16x16": "https://joeylene.com/favicon/favicon-16x16.png"
- createdAt: "Jan 01, 2022"
- updatedAt: "Feb 01, 2023"
- url: "https://joeylene.com"
- navigation:
- home: "/"
- about: "/about"
- blog: "/blog"
... other meta tags
---
# Hi, I'm Joeylene.
Product-focused software engineer experienced in building apps from the ground up.
## Builds apps from the ground up.
Currently a **Sr. Product Engineer** working on a browser-native gaming platform. I'm experienced with building products from the ground up due to working with early-stage startups.
On the side, I'm building [sutle.io](https://sutle.io), a platform for organizing resources into a directed learning path. I'm also dabbling in game development specifically learning Unity.
Mainly uses **ReactJS**, TypeScript, TailwindCSS, PostreSQL, and **Rails** but open to learning new things.
Currently [Jamango!](https://jamango.io/), previously at [Tonic Labs](https://toniclabs.ltd).
- [Mastadon](https://techhub.social/@jorenrui)
- [Twitter](https://twitter.com/jorenrui)
- [GitHub](https://github.com/jorenrui)
- [Blog RSS](https://joeylene.com/rss.xml)
- [Email Me](mailto:[email protected])
...Then the API for getting this result would be joeylene.com/export.md then for other pages it would be:
https://joeylene.com/blog/2022/creating-my-own-ui-componentstohttps://joeylene.com/blog/2022/creating-my-own-ui-components/export.md.https://joeylene.com/abouttohttps://joeylene.com/about/export.md.
Another example is for a Tweet, the markdown would look something like this:
# Jorenrui's Tweet
Pinned Tweet
[

](https://twitter.com/jorenrui)
[jorenrui](https://twitter.com/jorenrui)
[@jorenrui](https://twitter.com/jorenrui)
Sutle is now in beta with a new tech stack and a redesign. Also made a blog site for Sutle For now, I'll be doing minor updates and create a new portfolio next before doing any major updates on Sutle. [https://blog.sutle.io/2022/sutle-beta-a-fresh-redesign](https://t.co/as7YfVfoMB)
[

](https://twitter.com/jorenrui/status/1581975736860413954/photo/1)
[7:49 PM · Oct 17, 2022](https://twitter.com/jorenrui/status/1581975736860413954)Though I’m still contemplating whether it should be in JSON format or in markdown because currently I’m using MDX in rendering the pages using NextJS.
Having an exportable, standardized format like this, anyone can create a UI for it, just like how it is for RSS.
Another reason why I prefer a much simpler format, like the one above, is because it is hard to accurately replicate a web app in its current state. To do so, we need to list out all the hardware and software specifications that it needs in order to properly visualize what it is supposed to look like. Therefore, with a simpler format, you are exporting the content - the thing that really matters - regardless of the platform.
Versioning
Another issue worth focusing on is versioning. Since there is no versioning on the web, it is easy to update the content in a web page. This can lead to problems like content drift, and often the domain owner changes after a certain period of time, resulting in content that is very different from its original form. If you are referencing a link, you are usually referencing the content at that point in time, not the new content the new domain owner is displaying. Furthermore, versioning can help with historical revisionism.
If multiple users are able to export a web page, they can verify the validity of their copies of that web page by cross-checking it with each other’s copies.
Deletion
I think it’s important to also focus on deletion. Having no way to delete a version or a copy is a bug. There should be a way for users to make take-down requests, as everyone has a right to be forgotten. Examples of data that should be deleted include sites that display users’ private information, such as home addresses, without their consent; and sites that showcase revenge or child p*rn without the owner’s consent for their data to be shown publicly.
But I do think there can be a Prohibited Area in which banned sites are stored and only accessible to a select group of people for judicial/research purposes.
Architecture / Making sense of a solution
With that, here is a summary of the features that I think is needed to archive the web or do offline web surfing:
- Universal Format for the Content
- Should be simple and can point to other sources. Example format can be markdown or JSON.
- Every public page should be “exportable”.
- To replicate the “original format”, the hardware/software specs should also be recorded or listed.
- Versioning
- Prevents Content Drift
- External links has a version tag or timestamp to show that you are referencing a link at that point in time.
- Owner of the domain may change.
- Importance of Audit and Transparency - Multiple sources (big and small repositories)
- We can verifying copies/sources by checking other copies.
- Preventing history changes.
- Prevents Content Drift
- Deletion
- Takedown Requests.
- Prohibited area for research purposes.
If you take note, we can use how Git works in terms of version control when implementing it. Then, there will be local and remote copies of that site. Users can have a local copy and select a remote source to sync from.
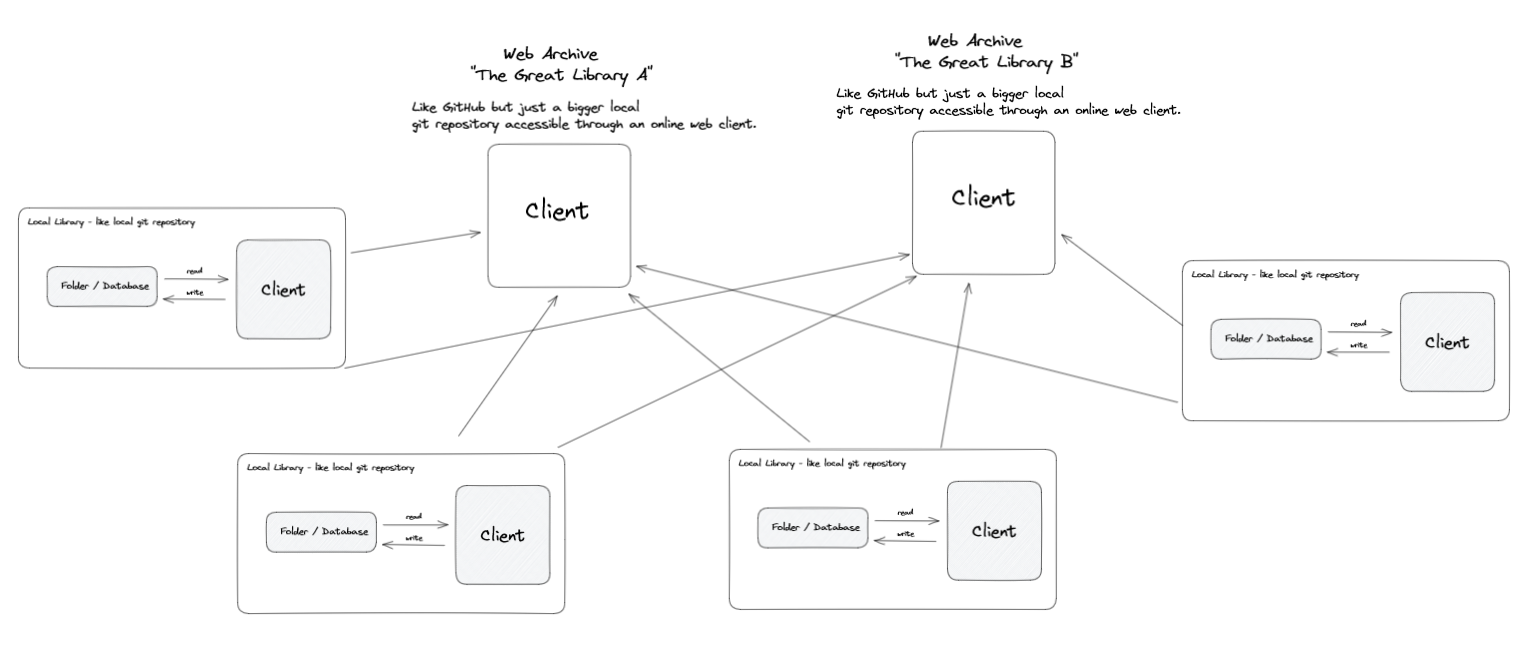
When bookmarking a site, I was thinking of a structure similar to this:

With this, users can even use a custom client in doing offline web surfing. For example, if we decided to export data in markdown, we can use a client like Obsidian in navigating those content.
As for deletion or the forbidden area, I haven’t thought of a flow for that yet. Maybe someday.
Thoughts
This was just an exercise that I did. I don’t really plan to implement this, especially since this requires everyone to have a universal format for exporting their sites.
For now, if you are referencing links for your research papers, I highly suggest using sites like Internet Archive and Perma.
Anyways, thanks for reading 🙇♀️